Evaluating Conversations in AI Insights
Use AI Insights’ conversation evaluation feature to collect structured feedback on your assistant’s interactions. You can define custom evaluation criteria, fill them automatically or manually, and enable the evaluation pipeline on new conversations.1. Overview
The evaluation form lets you specify exactly what and how to evaluate for each conversation:- Purpose: Gather consistent, structured assessments of assistant replies.
- Use cases: Quality control, performance tracking, fine‐tuning data collection.
- Modes:
- Automatic: Every new conversation is evaluated by a large language model (LLM) against your schema.
- Manual: Reviewers fill in the form via the UI, optionally assisted by the LLM.
2. Configuring the Evaluation Form
AI Insights uses a custom JSON Schema defintion for your form. You can describe each field’s:- Key (JSON property name)
- Type (
boolean,string,array, etc.) - Title and Description (guidance for the evaluator)
- Enum or Choices for list selections
3. Example: Defining Your Form
Below is a screenshot of the form editor in AI Insights: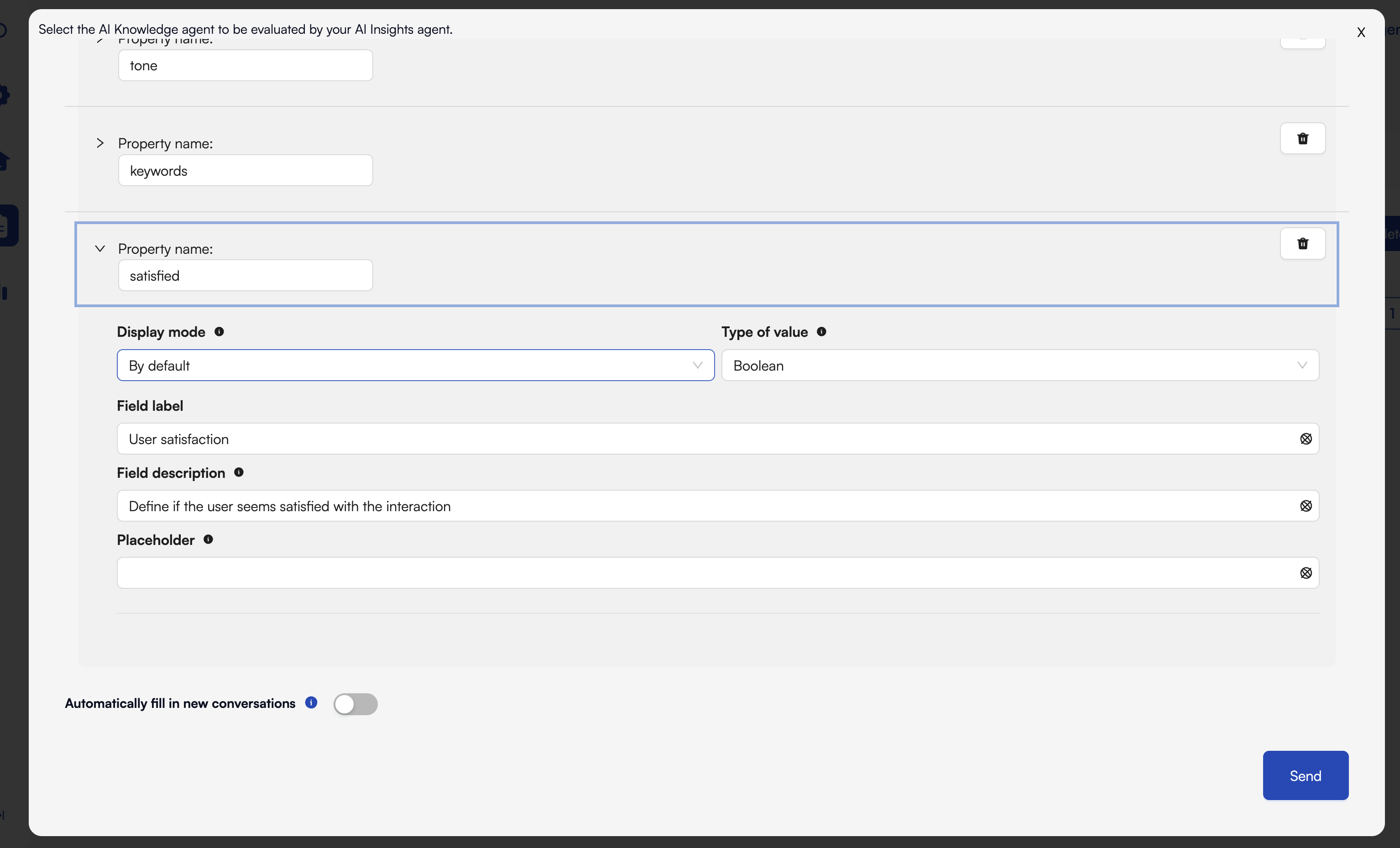
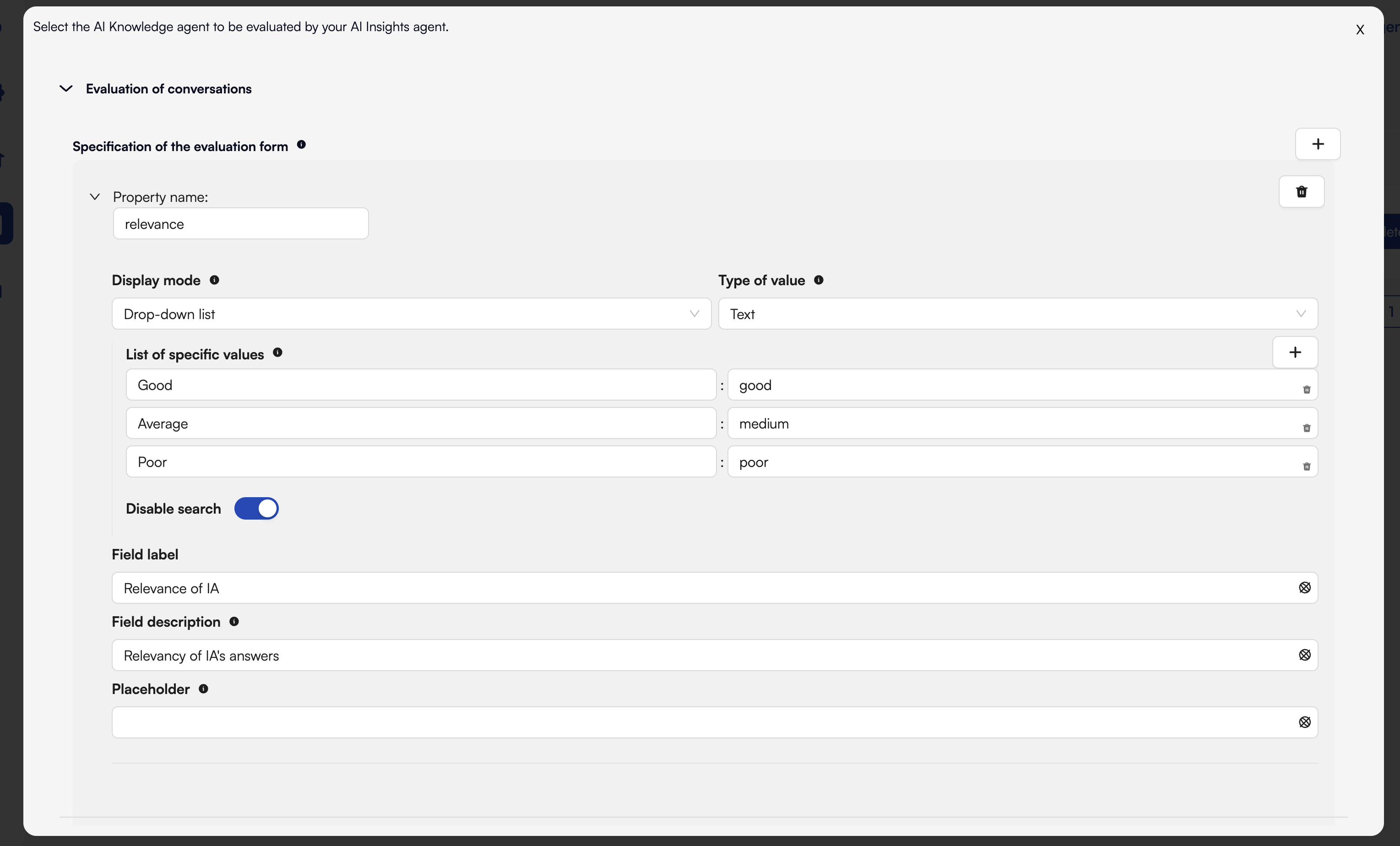
4. Using the Evaluation Form
4.1 Automatic Mode
To auto‐evaluate every new conversation:- Toggle Automatically fill in new conversations below your evaluation form.
- Save changes.
4.2 Manual Mode
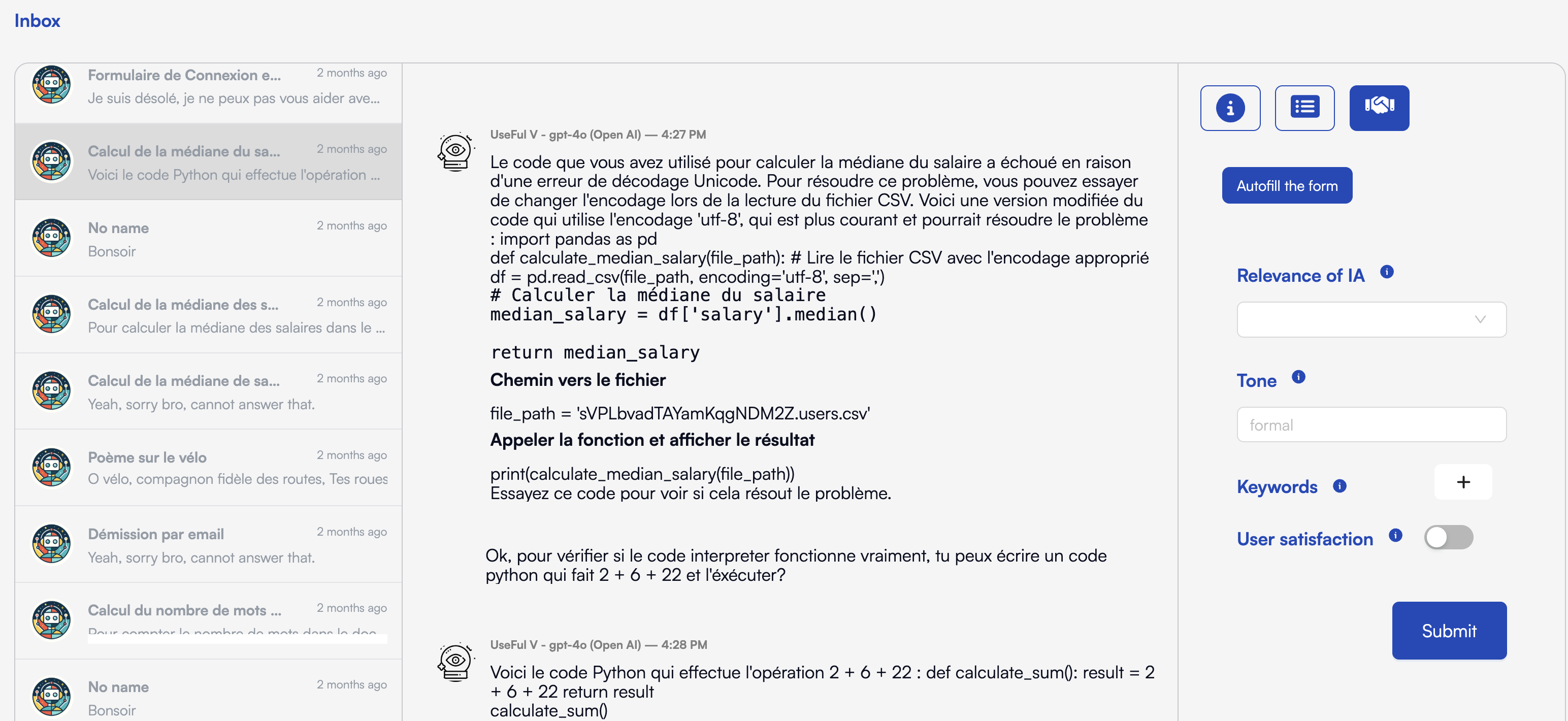
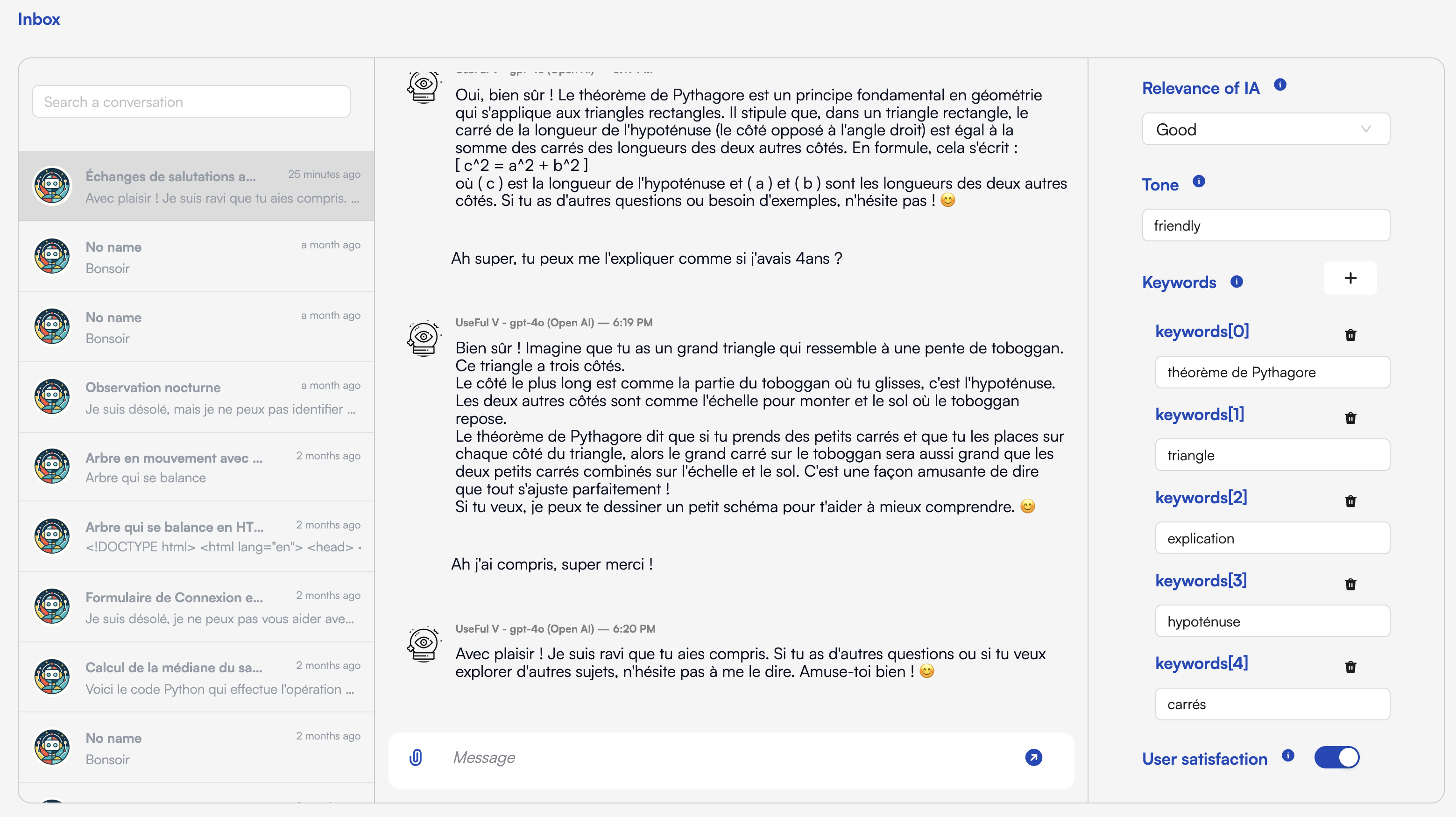
To review and evaluate on demand:- Open Inbox in the sidebar.
- Select a conversation thread.
- Click Evaluate in the top-right toolbar (the shaking hands icon).
- The evaluation form appears.
- Optional : ask the LLM to prefilled them with the “Autofill the form” button.
- Adjust fields as needed and Submit.
5. Best Practices
- Keep descriptions concise but informative.
- Limit required fields to key metrics.
- Use enums for common issues to standardize feedback.
- Regularly review schema based on evaluator feedback.
- Leverage LLM assistance for faster manual reviews.
Happy evaluating! 🎉